 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Few-Shot 3D Point Cloud Classification
Mar 31, 2023In recent years, research on few-shot learning (FSL) has been fast-growing in the 2D image domain due to the less requirement for labeled training data and greater generalization for novel classes. However, its application in 3D point cloud data is relatively under-explored. Not only need to distinguish unseen classes as in the 2D domain, 3D FSL is more challenging in terms of irregular structures, subtle inter-class differences, and high intra-class variances {when trained on a low number of data.} Moreover, different architectures and learning algorithms make it difficult to study the effectiveness of existing 2D FSL algorithms when migrating to the 3D domain. In this work, for the first time, we perform systematic and extensive investigations of directly applying recent 2D FSL works to 3D point cloud related backbone networks and thus suggest a strong learning baseline for few-shot 3D point cloud classification. Furthermore, we propose a new network, Point-cloud Correlation Interaction (PCIA), with three novel plug-and-play components called Salient-Part Fusion (SPF) module, Self-Channel Interaction Plus (SCI+) module, and Cross-Instance Fusion Plus (CIF+) module to obtain more representative embeddings and improve the feature distinction. These modules can be inserted into most FSL algorithms with minor changes and significantly improve the performance. Experimental results on three benchmark datasets, ModelNet40-FS, ShapeNet70-FS, and ScanObjectNN-FS, demonstrate that our method achieves state-of-the-art performance for the 3D FSL task. Code and datasets are available at https://github.com/cgye96/A_Closer_Look_At_3DFSL.
What Makes for Effective Few-shot Point Cloud Classification?
Mar 31, 2023



Due to the emergence of powerful computing resources and large-scale annotated datasets, deep learning has seen wide applications in our daily life. However, most current methods require extensive data collection and retraining when dealing with novel classes never seen before. On the other hand, we humans can quickly recognize new classes by looking at a few samples, which motivates the recent popularity of few-shot learning (FSL) in machine learning communities. Most current FSL approaches work on 2D image domain, however, its implication in 3D perception is relatively under-explored. Not only needs to recognize the unseen examples as in 2D domain, 3D few-shot learning is more challenging with unordered structures, high intra-class variances, and subtle inter-class differences. Moreover, different architectures and learning algorithms make it difficult to study the effectiveness of existing 2D methods when migrating to the 3D domain. In this work, for the first time, we perform systematic and extensive studies of recent 2D FSL and 3D backbone networks for benchmarking few-shot point cloud classification, and we suggest a strong baseline and learning architectures for 3D FSL. Then, we propose a novel plug-and-play component called Cross-Instance Adaptation (CIA) module, to address the high intra-class variances and subtle inter-class differences issues, which can be easily inserted into current baselines with significant performance improvement. Extensive experiments on two newly introduced benchmark datasets, ModelNet40-FS and ShapeNet70-FS, demonstrate the superiority of our proposed network for 3D FSL.
Point Cloud Instance Segmentation with Semi-supervised Bounding-Box Mining
Nov 30, 2021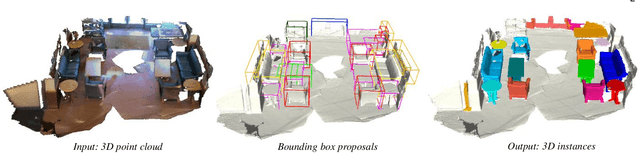
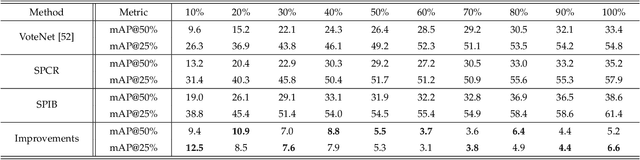
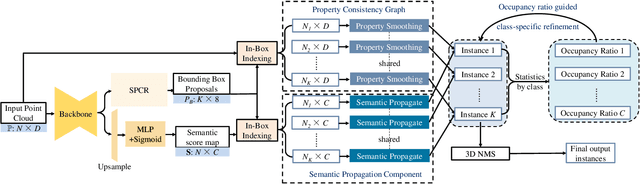
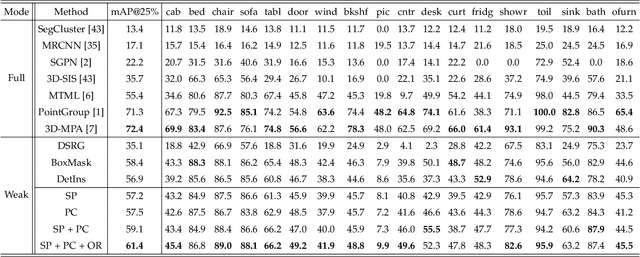
Point cloud instance segmentation has achieved huge progress with the emergence of deep learning. However, these methods are usually data-hungry with expensive and time-consuming dense point cloud annotations. To alleviate the annotation cost, unlabeled or weakly labeled data is still less explored in the task. In this paper, we introduce the first semi-supervised point cloud instance segmentation framework (SPIB) using both labeled and unlabelled bounding boxes as supervision. To be specific, our SPIB architecture involves a two-stage learning procedure. For stage one, a bounding box proposal generation network is trained under a semi-supervised setting with perturbation consistency regularization (SPCR). The regularization works by enforcing an invariance of the bounding box predictions over different perturbations applied to the input point clouds, to provide self-supervision for network learning. For stage two, the bounding box proposals with SPCR are grouped into some subsets, and the instance masks are mined inside each subset with a novel semantic propagation module and a property consistency graph module. Moreover, we introduce a novel occupancy ratio guided refinement module to refine the instance masks. Extensive experiments on the challenging ScanNet v2 dataset demonstrate our method can achieve competitive performance compared with the recent fully-supervised methods.